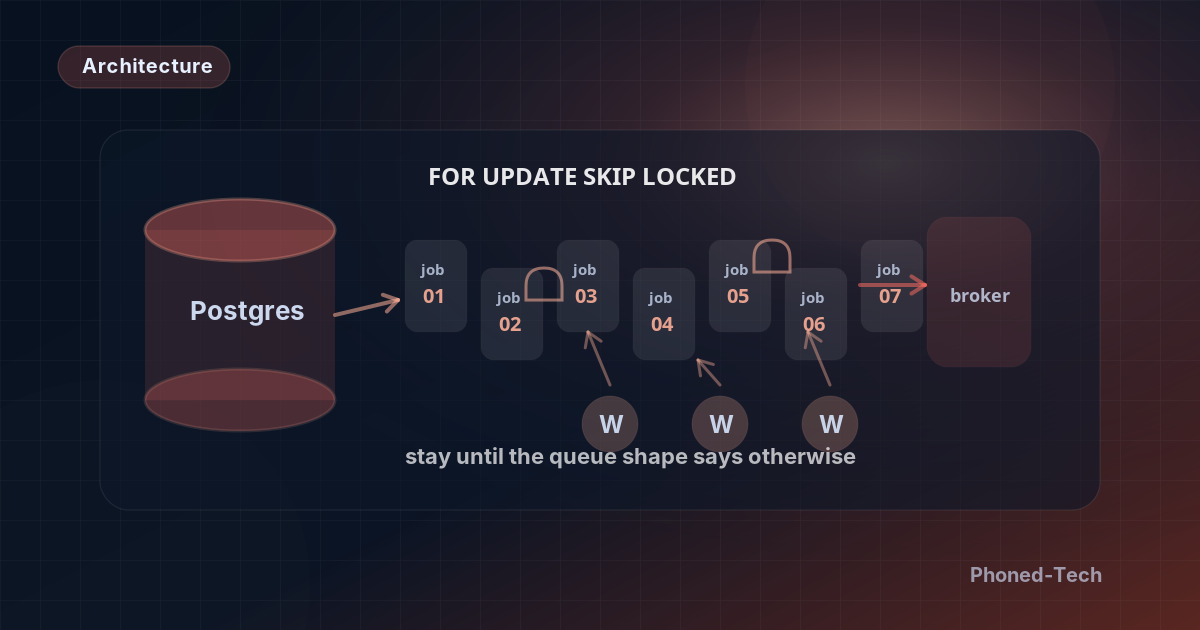
לחצי מהמערכות שביצענו עליהן audit בשנתיים האחרונות יש טבלת תור ב-Postgres. טבלת jobs עם עמודת status, חותמת זמן claimed_at, ו-worker שעושה polling. זה התור הזול ביותר שאפשר לבנות, ו-FOR UPDATE SKIP LOCKED גורם לו להופיע הרבה יותר טוב ממה שאנשים מצפים.
השאלה שהכי שואלים אותנו היא אם לעבור ל-broker אמיתי. התשובה כמעט תמיד היא ״עדיין לא״.
למה Postgres בסדר
לרוב ה-workloads, תור Postgres יחיד מטפל באלפי jobs לדקה בלי להזיע. הדפוס פשוט:
- worker מריץ
SELECT id FROM jobs WHERE status = 'pending' ORDER BY priority, created_at LIMIT 1 FOR UPDATE SKIP LOCKED - הוא מעדכן את השורה ל-
status = 'running'עםclaimed_at = now() - הוא עושה את העבודה
- על הצלחה הוא מוחק את השורה (או מעביר לטבלת היסטוריה); על כשל הוא מעלה counter של retry
SKIP LOCKED הוא הקסם. בלעדיו, כל worker היה נחסם על אותה שורה. עם זה, כל worker תופס את ה-job הבא הזמין בצורה אטומית. Postgres תומך בזה מאז 9.5.
היתרונות התפעוליים עצומים: אתם כבר מנטרים את Postgres, אתם כבר מגבים אותו, ה-jobs שלכם משתתפים באותן טרנזקציות עם נתוני העסק, ואתם יכולים לבצע שאילתה על התור עם SQL. Jobs שנכשלו הופכים לשאילתת DB רגילה, לא webhook לדשבורד של ספק.
מתי זה נשבר
שלושה סימפטומים אומרים לכם שהזמן לעזוב.
ראשון, table bloat. טבלת תור שקולטת מיליוני שורות ביום תצבור tuples מתים אפילו עם autovacuum. ברגע ש-VACUUM לא מצליח לעמוד בקצב, latency של שאילתה מתחיל לתנוד. Partitioning לפי תאריך עוזר; בסוף זה לא.
שני, צי ה-workers מתחיל להשתלט על חיבורי DB. חיבורי Postgres יקרים. אם אתם מריצים 50 workers שכל אחד מחזיק חיבור ארוך-טווח, אתם מבזבזים חצי מקיבולת ה-DB על התור. PgBouncer עוזר. גם הקטנת מספר ה-workers על-ידי הפיכת כל worker למהיר יותר.
שלישי, אתם צריכים fan-out אמיתי — job אחד מפעיל עשרה jobs במורד הזרם לרוחב מספר שירותים. Postgres יכול לעשות את זה עם LISTEN/NOTIFY, אבל המודל נהיה שביר. כאן broker אמיתי (NATS, Kafka, RabbitMQ, אפילו SQS + SNS) מצדיק את עצמו.
מסלול המיגרציה
עשינו את המיגרציה הזו שלוש פעמים. הדפוס שעובד:
תתחילו על-ידי בידוד הגישה לתור מאחורי interface. האפליקציה קוראת ל-Queue.enqueue(job) ו-Worker.handle(callback). המימוש הוא Postgres לעת עתה. ה-refactor הזה הוא חצי מהמיגרציה.
כשאתם מוכנים להחליף, תעשו dual-write לשבועיים. כל enqueue הולך גם ל-Postgres וגם ל-broker החדש. Workers צורכים מה-broker החדש. תור ה-Postgres פועל כפס התאוששות אם משהו משתבש. אחרי שבועיים, תזרקו את הכתיבה ל-Postgres.
אל תדלגו על שלב ה-dual-write. כל צוות שדילג עליו איבד jobs.
מימוד ההחלטה
הכלל המחוספס שאנחנו משתמשים בו: מתחת ל-100k jobs ביום, תישארו על Postgres אלא אם יש לכם צורך ספציפי. בין 100k ל-1M, תעריכו על-פי צורת ה-workload (יציב בסדר; בורסט יותר קשה). מעל 1M, בדרך כלל גדלתם מזה, ועלות ה-broker היא פריט קטן יותר לעומת הכאב התפעולי.
אזהרה אחת: אם ה-jobs שלכם צריכים הבטחות משלוח חזקות יותר מ-at-least-once עם workers idempotent, יש לכם בעיה אחרת, ו-Postgres הוא לא הצוואר. תפתרו idempotency קודם.