בכל פרויקט שיצא לפרודקשן אצלנו ב-18 החודשים האחרונים היה רכיב אחזור (retrieval). חלק מהפרויקטים האלה נקראו ״RAG״ בהצעת המחיר. רובם לא. הקיצור הזה הפך להיות כל-כך עמוס שהוא הפסיק לתאר את העבודה האמיתית.
כשלקוח מבקש ״מערכת RAG״, מה שהוא בדרך כלל רוצה זה אחד משלושה דברים: מנוע חיפוש שמחזיר הסברים במקום לינקים, צ׳אטבוט שמבסס את התשובות שלו על המסמכים שלו, או כלי פנימי שמאפשר למהנדס ג׳וניור לשאול שאלה של מהנדס סניור בלי לחכות לתשובה ב-Slack. אלה מוצרים שונים. הם חולקים ארכיטקטורה, אבל מצבי הכשל שלהם מתפצלים מהר.
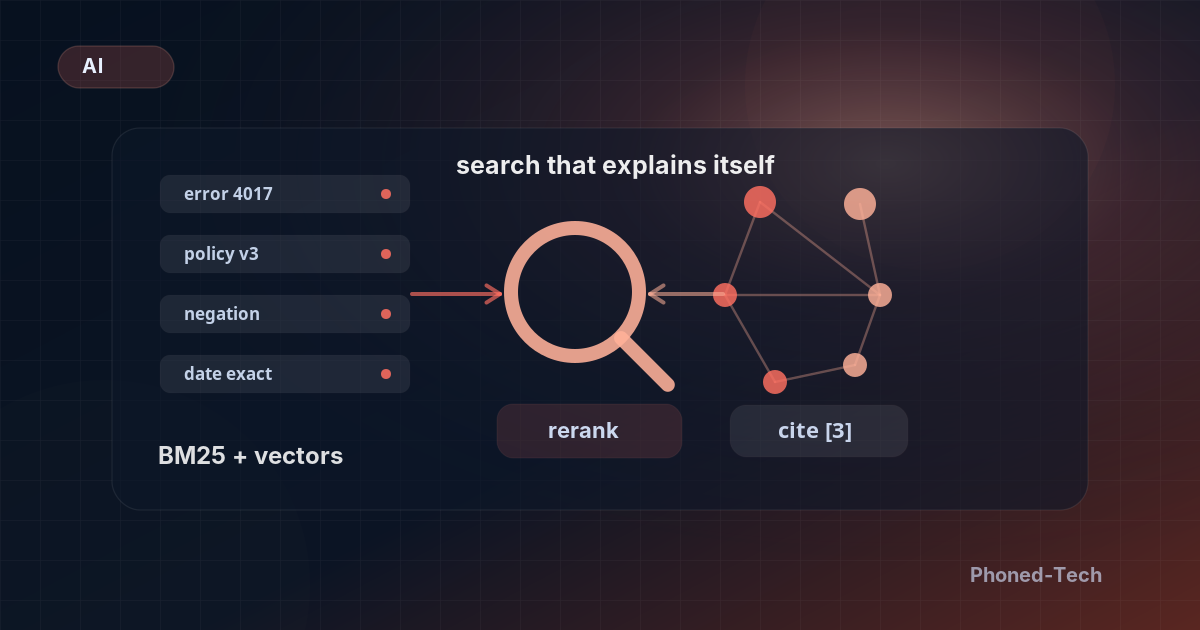
חיפוש ווקטורי לבד הוא מלכודת
אנחנו עדיין רואים צוותים שמשלחים מימושים pure-vector. עושים embedding לכל דבר, שומרים ב-vector DB, מבצעים שאילתה ב-cosine similarity, ושולחים את ה-top-k צ׳אנקים ל-LLM. זה מדגים יפה. זה גם נכשל בכל שאילתה שמכילה מספר חלק, תאריך, ביטוי מדויק, או שלילה.
חיפוש ווקטורי טוב בדמיון סמנטי. הוא לא טוב בהתאמה מדויקת. משתמש שמקליד error code 4017 לא רוצה מסמכים שהם ״על שגיאות״ — הוא רוצה את הדף שמכיל את ארבעת התווים האלה בסדר הזה. אינדקס מילות מפתח מטפל בזה תוך מילישניות. ווקטורים — לא.
התיקון הוא אחזור היברידי: להריץ BM25 (או Postgres full-text) ושאילתת וקטור במקביל, ואז לבצע re-rank על האיחוד. אנחנו משתמשים ב-Reciprocal Rank Fusion כשאין תקציב ל-re-ranker, וב-cross-encoder כשיש. העלות היא אינדקס נוסף ושאילתה נוספת לכל בקשה. הזכייה היא שהמערכת מפסיקה להיראות מטופשת בשאילתות שהמשתמשים שלך באמת מקלידים.
Re-ranking הוא המקום שבו תקציב ה-latency הולך
אם יש לך רק 1.2 שניות end-to-end, אתה לא יכול להרשות לעצמך לקרוא ל-re-ranker של 400ms על גבי קריאת אחזור של 200ms. למדנו לעשות את זה בשלבים: להחזיר 50 מועמדים בשאילתה זולה, לבצע re-rank רק כשציון ה-top-1 הוקטורי מתחת לסף (המודל לא בטוח), ולוותר על ה-re-ranking לגמרי כשהשאילתה של המשתמש תואמת בדיוק כוונה ידועה.
גנב ה-latency השני הוא קריאת המסמכים עצמם. אם הצ׳אנקים שלך חיים ב-S3 ואתה שואב אותם on-demand, הוספת 80ms לכל צ׳אנק. שמור את הצ׳אנקים במטמון ב-Redis או, יותר טוב, אחסן אותם ליד האינדקס. עלות האחסון השולית היא אפסית לעומת מס ה-latency.
ציטוטים או שזה לא קרה
משתמשים לא יסמכו על מערכת AI שמצהירה בביטחון משהו שאין להם דרך לוודא. כל תשובה צריכה ציטוט בחזרה לצ׳אנק המקור, וכל ציטוט צריך להיות לינק אמיתי שהמשתמש יכול ללחוץ עליו. שלחנו מערכות שבהן הציטוטים זויפו על-ידי ה-LLM (הוא הכיר את הפורמט, אז הוא ייצר URLs מתקבלים על הדעת). מחלקת המשפטים שמה לב לפני המשתמשים.
בנו את טיפול הציטוטים מחוץ למודל. תעבירו לכל צ׳אנק שאוחזר ID מספרי קטן. תגידו למודל להשתמש ב-IDs האלה בתשובה. אחרי הג׳נרציה, תפענחו את ה-IDs ותרנדרו את הלינקים האמיתיים מתוצאת האחזור שלכם. המודל אף פעם לא רואה URL, אז הוא לא יכול להזות אחד.
Evals לפני ההשקה, evals אחרי
ההבדל בין ״עובד בהדגמה״ ל״עובד בפרודקשן״ הוא סוויטת evals. שלנו יש שלוש שכבות: בדיקות אחזור דטרמיניסטיות (האם שאילתה X מחזירה צ׳אנק Y ב-top-3?), בדיקות תשובה מבוססת (האם המודל אומר את מה שציפינו, בהינתן אותם צ׳אנקים?), ורגרסיה end-to-end (שאילתה מלאה, תשובה מלאה, מצוינות על-ידי מודל חזק יותר).
אנחנו מריצים אותן ב-CI בכל שינוי פרומפט, ומריצים מחדש את הסוויטה המלאה שבועית מול דגימות תעבורת פרודקשן. בשבוע שבו שילחנו את מודל Claude החדש של Anthropic, סוויטת ה-evals תפסה רגרסיה בטיפול בשלילה שההדגמה לעולם לא הייתה חושפת. עשינו rollback, תיקנו את הפרומפט, שילחנו יומיים אחר כך.
מה אנחנו שולחים עם כל מימוש
אחרי ארבעה בילדים בפרודקשן, רשימת ה-deliverables התייצבה: retriever היברידי (BM25 + ווקטורים), re-ranker שמופעל בתנאים, מטמון צ׳אנקים, parser ציטוטים, harness של evals עם לפחות 50 בדיקות התחלה, ודשבורד קטן שמציג latency שאילתה, recall של אחזור, ודיוק תשובה מבוססת. הדשבורד הוא מה שמעיר אותנו כשמשהו סוטה. בלעדיו, אתה מגלה מהלקוח.
תקראו לזה RAG אם זה עוזר לטופס הרכש. פנימית, תקראו לזה מה שזה: חיפוש שמסביר את עצמו, עם הקבלות להוכחה.